A common developer experience across accelerator architectures
oneAPI is an open, multiarchitecture, multivendor programming model that lets developers use a single modern codebase across accelerators for faster application performance, more productivity, and greater innovation. The oneAPI specification includes six core elements for creating parallel applications.
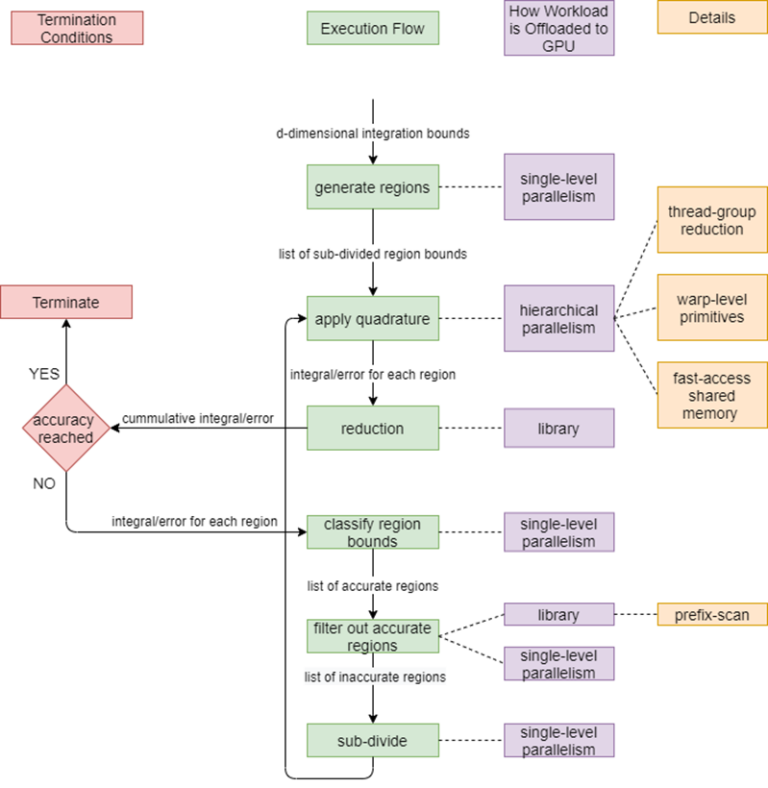
Parallel application development is a combination of API programming, where the parallel algorithm is hidden behind an API provided by the system, and direct programming, where the application programmer writes the parallel algorithm.
API programming
When using API programming, a developer implements performance-critical sections of the program with library calls. Well-defined and mature problem domains have high-performance solutions packaged as libraries.
- oneAPI defines a set of APIs for the most commonly used data-parallel domains.
- oneAPI platforms provide library implementations across a variety of accelerators.
Where possible, the API is based on established standards like BLAS. API programming enables programmers to achieve high performance across a diverse set of accelerators with minimal coding and tuning.
Direct programming
Some problem domains are not well suited to API programming because no standard solution exists or because solutions require a level of customization that cannot be easily implemented in a library. In this case, a developer uses direct programming and must explicitly code the parallel algorithm.
- oneAPI’s programming model is based on data parallelism, where the same computation is performed on each data element, and parallelism of the application scales as the data scales.
By allowing programmers to express parallelism directly, data-parallel algorithms make it possible to productively create highly efficient algorithms for parallel architectures.
Data-parallel algorithms are used for many of the most computationally demanding problems, including scientific computing, artificial intelligence, and visualization, and can be efficiently mapped to a diverse set of architectures: multi-core CPUs, GPUs, systolic arrays, and FPGAs.
Start building and contributing
The UXL Foundation encourages collaboration on the oneAPI specification and compatible oneAPI implementations across the ecosystem.
Join UXL to participate in working groups and special interest groups evolving and expanding the oneAPI specification and oneAPI open source projects for accelerated computing.
Specification elements
Become a member